Case Study: Catalyst Repository Systems selects a Language Detection Toolkit
Case Study: Selecting an Automatic Human Language Detection Toolkit for Legal War Room Software
Catalyst Repository Systems, Inc. (formerly CaseShare) handles huge volumes of random documents for their clients who are engaged in high volume document discovery in the legal space, part of the rapidly expanding eDiscovery market. Not only do large companies routinely have documents in different languages, for some of their clients up to one quarter of the content contains multiple languages in individual documents.
This presented a large technical problem that Catalyst needed to solve. Many Knowledge Management functions that casual users take for granted, such as fulltext search, actual require accurate detection of content’s language. Getting this wrong can cause retrieval failures caused by incorrect tokenization, stemming, entity extraction, thesaurus handling and other advanced language features. Having multiple languages routinely mixed within individual documents makes this even more complex. More than an inconvenience, failures in the eDiscovery can have legal and financial consequences for clients.
It is in this backdrop that the Catalyst technical team undertook their research. The goal? To find a reliable and controllable set of tools for multi-language document detection. Although open source candidates took center stage in this research, it wasn’t necessarily for savings on licensing fees. The open source ecosystem provides a wider diversity of features in some technical areas, and the open source transparency of source code allows for a deeper understanding of features and implementation, and also an opportunity for finer grain control.
This case study, authored by Cody Collier, Matthias Johnson, and Bruce Kiefer at Catalyst, gives some background on the subject, introduces the technical landscape and problem scope, then moves on to examine the various candidate libraries, and the Catalyst team’s ultimate findings. In terms of full disclosure, we are proud to call Catalyst a repeat NIE client.
Introduction
To achieve the goals of making global information retrievable, there is a tight relationship between encoding, language, tokenization, and stemming. Nearly every data platform is converging upon Unicode and specifically UTF-8 to normalize the encoding of data. As such, nearly every data platform needs to convert documents from their native encoding into UTF-8. Encoding is often a fact of the document, but if those facts are missing, encoding detection is an educated guess. Once the document has been converted from the native encoding into UTF-8, it needs to be tokenized. Tokenizers or word-breakers create the tokens from the document’s text. The tokens are the unit of search-ability in full text engines. For Latin based languages, tokenization is often not much more involved than splitting incoming text into words using white space as the cleavage point. Tokenization is tightly linked to stemming. Stemming is sometimes broken into stemming and lemmatization, but this is mostly just the choice of a vendor for marketing purposes.
For an overview of stemming, see What's the difference between Stemming and Lemmatization
To correctly stem we need the right tokens. To get the right tokens, we need to apply the right tokenizer. To get the right tokenizer, we need to know the language of the text we are indexing. Language and encoding are related, but not the same. For example, much of French, Spanish, and English can be expressed using the lower number Unicode code points from UTF-8 (think of your ASCII table). "Chat" is a valid word in English and French. In English, it tends to be a verb describing some form of oral communication or some form of instant messaging. In French, it means "cat". Neither of these interpretations has challenging stemming options, but it would be hard to guess the language being implied with a flexible word like "chat". Some codepoints are tightly aligned with language. For example, Hebrew codepoints are not used in many other languages. Like Latin languages, some of the Asian languages also share codepoints so it can be difficult to use encoding as a way to infer language.
Some documents can describe the language of their content. XML has this ability. HTML also has this ability. In practice these descriptive markups are not treated with the care needed to produce accurate results. You can often find "charset=UTF-8" in many web sites and they were likely created with Mac OS Roman or Windows Latin encodings. They can be converted to UTF-8, but the markup isn't quite accurate. Similarly, many web documents declare a language in the head of the document and ignore markup of other languages used within the same document.
Since detecting codepoints may not always lead to the language of the document and because document markup isn't always accurate, tools are needed to detect the language of the document. There are many tools available to choose from.
Language Detection at Catalyst
At Catalyst we serve a broad and international client base. Often this brings us documents in a variety of languages. Currently we host over millions of documents in 55 languages. These languages include many western languages as well as many Asian languages. Reflecting the nature of the digital world and ease of document flow across borders and cultures, virtually all of our clients are dealing with content in more than one language.
We are seeing larger numbers of the following languages:
- ja (Japanese)
- ko (Korean)
- es (Spanish; Castilian)
- de (German)
Language detection across a document is challenging since often documents contain more than one language. For example an email can be written mostly in English, but can contain some small portions in Korean or Chinese as part of a formal greeting. Choosing the correct language and tokenizer is difficult.
Another difficulty arises when the search is issued. Tokenization is applied to the query text in an attempt to match the same tokens generated during the indexing. If the tokens are generated using different tokenizers, the mismatch will not yield the expected results. For example if some Korean text was tokenized based on Japanese, the search for a Korean tokenized search may return incorrect results.
While on average only 1.10% of all documents contain more than one language, some of our more international clients are seeing single document mixed language content exceeding 25%.
This is driving a need toward language detection on a smaller than document level scale to permit better capture and searching of multi-language content. Therefore our needs are focused on identifying not only the best tool for language detection, but also determining the most reasonable sized content which can be reliably detected.
The Language Detection Candidate Systems
In our search for a suitable language detection tool, we settled on five candidate systems for evaluation. The five candidates were:
- Google AJAX Language API (http://code.google.com/apis/ajaxlanguage/)
- Lingua::Ident (http://www.dynalabs.de/mxp/perl/lingua-ident.html)
- Pseudo (http://www.boxoffice.ch/pseudo/)
- TextCat (http://www.let.rug.nl/~vannoord/TextCat/)
- Xerox Language Guesser (http://orchid.xrce.xerox.com)
The Language Samples
In order to test each detection system, we needed samples of text from a variety of languages. The samples in such a test can have a strong affect on the results, favoring one system or another depending on the languages supported. One could spend many hours searching for, collecting, and identifying language samples. Our business drivers usually lead us to more pragmatic approaches. In this case, we started with two prepared sample sets, taken from two of the detection systems themselves, and made slight modifications to fit our needs.
Sample Set A
Our first source of language samples was the set of sample files from TextCat, found online at http://www.let.rug.nl/~vannoord/TextCat/ShortTexts/. We downloaded these sample files, and then by hand, extracted a few sentences from each to create our Sample A set of text files. This set consisted of 75 different samples and languages.
During the word count to accuracy correlation testing, described later in the article, we extracted the words from Sample Set A.
Sample Set B
Our second language sample set was based on the sample text found on the Xerox website for their Language Guesser system at http://www.xrce.xerox.com/competencies/content-analysis/tools/guesser.en.html. These samples are relatively short and needed no further processing beyond extraction to various text files. This set consisted of 46 different samples and languages.
Sample Set C (word count samples)
For the word count tests we returned to the TextCat sources, as in set A. This time though, we programmatically extracted N words from the each language sample, with N = 2,3,4,5,6,7,8,9,10,15,20,25, and 30. This resulted in 13 sample sets, each containing N words from the 75 languages. Finally, to help mute problems from selecting “bad” words, we created 5 variations of these 13 sample sets. Imagine in variation one, for the 2 word set, we selected words 5 and 6, then for variation two we selected words 15 and 16 and so on.
Testing Overview
Our testing focus was on Language Detection accuracy. No detection system can be expected to be 100% accurate under all conditions. However, could we identify one system that consistently was more accurate than the others? We avoided measuring performance at this stage, and we disregarded measures of confidence produced by some of the systems.
Lingua, Textcat, and Pesudo were installed on an internal web server and made programmatically accessible via an HTTP GET to a URL. The Xerox system is available as a SOAP web service. A local web server and script was used to interact with the Google AJAX service. This web service oriented setup allowed for a common testing pattern of selecting sample text, performing an HTTP GET with the text in the query string, and then parsing and normalizing the results of the detection system.
It's important to note that each system returns detection results using slightly different language names and/or language codes. To help normalize the language codes, we lightly processed language labels and then attempted to match a language in the ISO 639-3 code table (http://www.sil.org/iso639-3/iso-639-3_20090210.tab) which encompasses ISO 639-1, ISO 639-2, ISO 639-3, and a reference name. This normalization system doesn't identify all cases, but worked well enough for our testing efforts.
Testing Detection Accuracy
For a simple test of detection accuracy, we ran each detection system against each sample set. The summary of the results is found below, with each line item numbered for reference.
Results of tests against sample set A
- system: TextCat -- first guess accuracy: 94.67% (71 of 75 correct)
- system: Pseudo -- first guess accuracy: 92.00% (69 of 75 correct)
- system: Google -- first guess accuracy: 46.67% (35 of 75 correct)
- system: Lingua -- first guess accuracy: 40.00% (30 of 75 correct)
- system: Xerox -- first guess accuracy: 10.67% (8 of 75 correct)
Results of tests against sample set B
- system: TextCat -- first guess accuracy: 46.67% (21 of 45 correct)
- system: Pseudo -- first guess accuracy: 75.56% (34 of 45 correct)
- system: Google -- first guess accuracy: 75.56% (34 of 45 correct)
- system: Lingua -- first guess accuracy: 28.89% (13 of 45 correct)
- system: Xerox -- first guess accuracy: 88.89% (40 of 45 correct)
The summary results mask various issues such as problems with language code normalization and lack of support for certain languages in a detection system. Obviously, these results should not be accepted as authoritative for all contexts and you should perform your own due diligence as required. For our needs, these tests were able to serve as an adequate heuristic for early selection of a system. If you're interested in greater detail, you're urged to contact the authors.
The tests against sample set A showed TextCat and Pseudo to be the early leaders in terms of accuracy. Remember that sample set A is a subset of the language samples that accompany TextCat. As a result, there is likely a positive bias expressed in TextCat's performance against this set. Google's detection system misidentified many of the results as Swahili and Lingua had no guess for many of the samples. It's unclear at this time whether the poor results reflect on the detection itself or perhaps some other compatibility or translation problem with the samples. Finally, the Xerox Language Guesser show's a misleading 10.67% accuracy. This result was so low because the Language Guesser performs a validation prior to attempting a language guess and almost all of the samples were rejected with the error "Invalid byte 2 of 3-byte UTF-8 sequence". Our requirements include the need to make a guess despite malformed text in real world documents, so no further investigation was made.
The tests against sample set A helped show that the choice of samples can have a dramatic effect on measured results of a detection system. Again, likely positive bias was expressed in Xerox's detection tool performing the best against its own sample set derivative. Pseudo continued to perform relatively well in terms of accuracy. TextCat had a drop in performance compared to sample set A, Google's API had an increase in performance, and Lingua again performed poorly.
With these results, it was time to make some decisions and see if we could combine the results with our business requirements and eliminate any candidates. Right away, we eliminated the Xerox Language Guesser because of the validation feature. The Google API was eliminated because it wasn't a superstar performer, so there was nothing to balance against the odd terms of service (storage of results beyond 14 days is not allowed) and potential hurdles of a remote web service. Finally, the poor performance of Lingua allowed us to remove that system from contention.
This process left us with a choice between TextCat and Pseudo. Rather than further testing with potentially diminishing returns we opted to select the better average performer Pseudo and push it to trial in production, with TextCat serving as a backup selection. The intricacies around normalization of language codes as well as language samples means we're likely better off spending our time training and tuning around a single selected system than trying to further refine the testing. Your requirements and application may vary with your own context.
Testing the Effects of Word Count on Accuracy
In addition to testing general accuracy of the language detection systems, we were interested in determining the effect of word count on language detection accuracy. Should we perform language detection against words, sentences, paragraphs, or whole documents? In constructing a document preparation pipeline, there are costs associated with trying to detect language at the document or sentence level. Submitting a single document for language detection is efficient, but could be inaccurate or costly with a large payload. Submitting sentences repeatedly means more time in the preparation pipeline and more calls to the language detection service. Documents representing email are particularly troublesome because of short answers creating short paragraphs. Short candidate phrases can produce unintended results as noted below.
For the word count testing, we used the four locally installed (Pseudo, Textcat, Lingua, Google AJAX API) detection systems and excluded the Xerox system. For the language samples we used Sample Set C as described earlier in the text. As a reminder, there are 5 variants of 13 sample sets of N words each with N = 2,3,4,5,6,7,8,9,10,15,20,25, and 30.
The results of these tests are better summarized in graph form, as seen here:
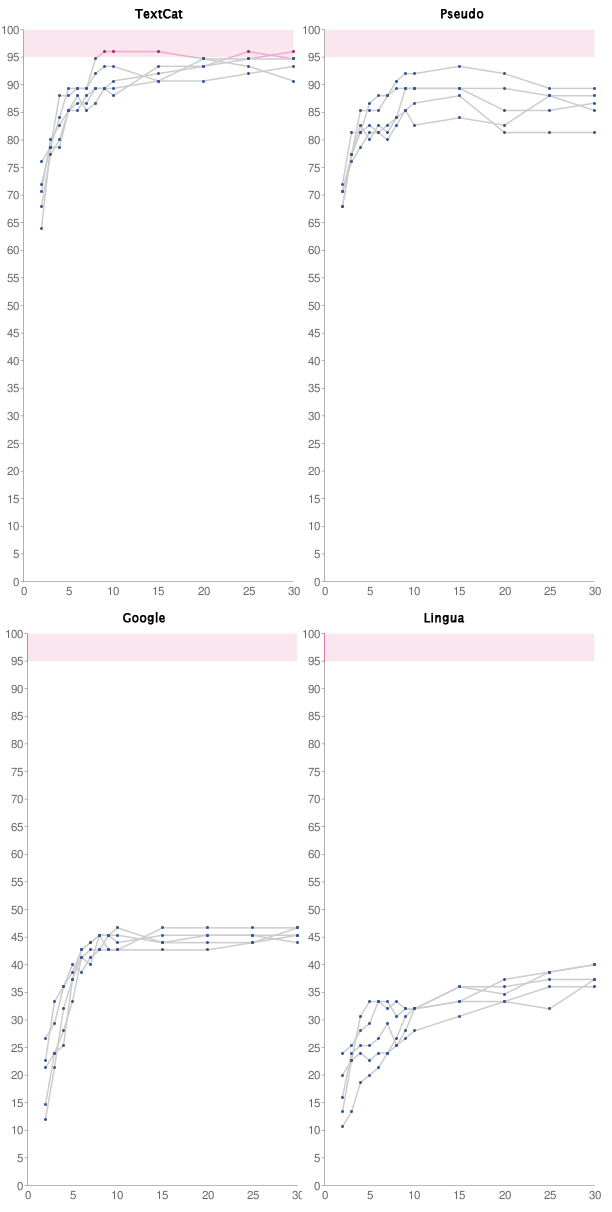
Fig 1: Results for TextCat, Pseudo, Google and Lingua
Along the X axis you'll see the 13 word counts N (2-30 words). Along the Y access is the accuracy percentage (0-100%). Each line represents a test against one of the 5 sample set variants.
For each system, note that the slope of accuracy begins to stabilize at about 10 words. This happens no matter what level of accuracy is being achieved. From this test, we can reasonably conclude that with these detection systems we should use samples of at least 10 words when trying to obtain a language detection guess.
Conclusion
By our criteria, both TextCat and Pseudo seemed like potentially acceptable solutions; we decided to move forward Pseudo, with TextCat as a backup plan. The Xerox tool was too concerned with underlying character encoding errors for our particular requirements, which must be able to operate with relatively unpredictable “dirty” data. Lingua and Google were dropped for other reasons, but “your mileage may vary”.
It appears that you need at least a ten word sample of text to get decent performance from any language detection engine. This would imply that accurately recognizing very short passages of text, such a sentence in one language quoting a speaker of another language, would be quite difficult.